I use next.js and mdx plugin to build my blog site. It's a next.js SSG project.
Also it's a JAMStack site. So i need a extenal search engine.
The Algolia is my first choice. We can build our own Algolia front UI, or use DocSearch

Purpose
Algolia split DocSearch into to parts:
-
A cralwer to crawl our sites.
-
A frontend UI liburary to show search result.
In legacy edition, Algolia provide a docsearch-scraper to build our own crawler.
Although it's still can plug it to DocSearch v3. But now it's deprecated.
They introduct the Algolia Crawler web interface to manage the crawler.
But i can't login with my Algolia account.
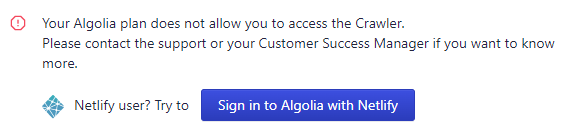 Can't login to Algolia Crawler
Can't login to Algolia Crawler
So i need find another way to generate my post index.
Index format
The DocSearch frontend UI read result as specific format. We just need to provide the same format to DocSearch.
Then DocSearch fronted UI can works.
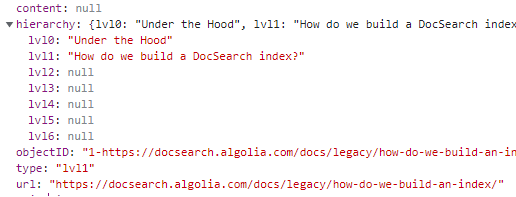 Index format
Index format
So we need post same format to Algolia.
Push our data
Algolia provide JavaScript API Client to push data to Algolia.
yarn add algoliasearch
npm install algoliasearch
The client will help us push data to Algolia. We just need to prepare out data.
Docsearch format
Because Docsearch read result as specific format. our data need to be like this:
{
content: null,
hierarchy: {
lvl0: 'Post',
lvl1: slug,
lvl2: heading,
},
type: 'lvl2',
objectID: 'id',
url: 'url',
}
Generate format
For generate our data, we need:
- dotenv: read Algolia app ID and admin key in
.envfile. - algoliasearch: JavaScript API client.
fsandpath: read post file.- nanoid (optional): generate unique
objectID.
For use ECMAScript import, we need set file suffix with .mjs. The node.js can use import statement.
// build-search.mjs
import { config } from 'dotenv';
import algoliasearch from 'algoliasearch/lite.js';
import fs from 'fs';
import path from 'path';
import { nanoid } from 'nanoid';
Next, read post content from file. First we need read whole content from the file:
const files = fs.readdirSync(path.join('pages/p'));
Then, prepare a empty array to store post data. And traverse content to generate format we need.
const myPosts = [];
files.map((f) => {
const content = fs.readFileSync(path.join('pages/p', f), 'utf-8');
// const { content: meta, content } = matter(markdownWithMeta);
const slug = f.replace(/\.mdx$/, '');
const regex = /^#{2}(?!#)(.*)/gm;
content.match(regex)?.map((h) => {
const heading = h.substring(3);
myPosts.push({
content: null,
hierarchy: {
lvl0: 'Post',
lvl1: slug,
lvl2: heading,
},
type: 'lvl2',
objectID: `${nanoid()}-https://rua.plus/p/${slug}`,
url: `https://rua.plus/p/${slug}#${heading
.toLocaleLowerCase()
.replace(/ /g, '-')}`,
});
});
The type property means level of table of contents.
I just need h2 title in search result. So just match them with /^#{2}(?!#)(.*)/gm.
And post title is the lvl1 type:
myPosts.push({
content: null,
hierarchy: {
lvl0: 'Post',
lvl1: slug,
},
type: 'lvl1',
objectID: `${nanoid()}-https://rua.plus/p/${slug}`,
url: `https://rua.plus/p/${slug}`,
});
Push to Algolia
Algolia API is easy to use. First we need specify the index name.
const index = client.initIndex('rua');
And save the objects.
const algoliaResponse = await index.replaceAllObjects(posts);
All done!
